ページの作成
親となるページを選択してください。

親ページに紐づくページを子ページといいます。
例: 親=スポーツ, 子1=サッカー, 子2=野球
子ページを親ページとして更に子ページを作成することも可能です。
例: 親=サッカー, 子=サッカーのルール
親ページはいつでも変更することが可能なのでとりあえず作ってみましょう!
| この記事の要点 |
|
Excel で指数表記になる条件
Excel は次の場合に自動的に「1.23E+10」のような指数表記にします:
- 数値が12 桁を超える(例: 123456789012 → 1.23457E+11)
- セル幅が狭く、通常表記で表示しきれない
- セルの書式が「指数」または「標準(広い列幅でなお桁が多い)」
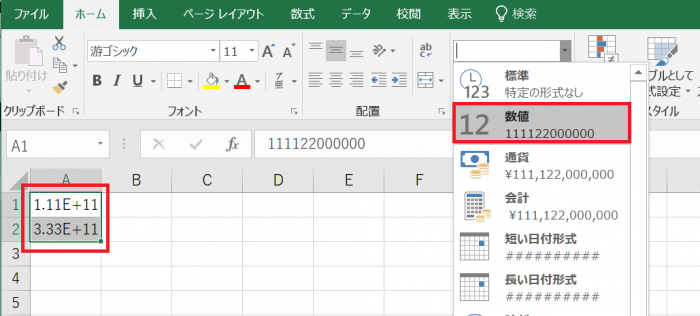
方法1: セル書式設定で「数値」に変更
- 対象セルを選択
- 右クリック → セルの書式設定(
Ctrl + 1) - 「表示形式」タブ → 「数値」
- 小数点以下の桁数を 0 に設定 → OK
ただしこれで直るのは表示だけ。データ自体が 16 桁ならば 16 桁目以降は 0 に丸められた状態で保存される(Excel の数値精度は 15 桁)。
方法2: 16 桁以上は文字列として扱う
クレジットカード番号やバーコード番号など、16 桁以上の数字をそのまま保持したい場合:
- セルを選択 → 書式設定 → 「文字列」
- 入力時に先頭に
'(シングルクォート)を付ける:'1234567890123456 - 入力後、Enter で
'は消えて表示は数字のみ、内部は文字列扱い
方法3: TEXT 関数で文字列化
=TEXT(A1, "0") ' 整数として文字列化(指数解除)
=TEXT(A1, "#,##0") ' 桁区切り付き
=TEXT(A1, "0000000000") ' 0 埋め 10 桁
=TEXT(A1, "0.00") ' 小数 2 桁方法4: 数値として扱いたいなら掛け算
CSV インポート等で文字列として読まれてしまった数字を再度数値化:
=A1*1 ' 単純な乗算で数値型に
=VALUE(A1) ' 専用関数
=NUMBERVALUE(A1) ' 地域別小数点に対応CSV インポート時に指数化を防ぐ
CSV の数値列が自動的に指数表記化されるのを防ぐ最も確実な方法:
- Excel を開いて新規ワークブック
- データタブ → 「テキストまたは CSV から」
- 該当列のデータ型を「テキスト」に指定
- 読み込み
あるいは CSV を直接ダブルクリックで開くのではなく、上記手順で必ずインポートウィザード経由で開くこと。
Python pandas での指数表記
import pandas as pd
df = pd.DataFrame({'id': [1234567890123, 1.5e15]})
print(df)
# 出力例(指数表記):
# id
# 0 1.234568e+12
# 1 1.500000e+15
# 解除1: 表示オプション
pd.set_option('display.float_format', '{:f}'.format)
print(df)
# 0 1234567890123.000000
# 1 1500000000000000.000000
# 桁数を 0 に
pd.set_option('display.float_format', '{:.0f}'.format)
# リセット
pd.reset_option('display.float_format')
# 解除2: 列の型を int に
df['id'] = df['id'].astype('int64')
# 解除3: Excel 出力時の指数化防止
df.to_excel('out.xlsx', index=False) # 大きい数は文字列で書くのが安全
df['id'] = df['id'].astype(str)
df.to_excel('out.xlsx', index=False)Python 標準フォーマット
x = 1.234e10
# f-string
print(f'{x:.0f}') # 12340000000
print(f'{x:,.0f}') # 12,340,000,000
print(f'{x:e}') # 1.234000e+10(指数表記)
# format 関数
print(format(x, '.0f')) # 12340000000
print(format(x, ',.2f')) # 12,340,000,000.00
# 古い % 記法
print('%d' % x) # 12340000000
# numpy
import numpy as np
np.set_printoptions(suppress=True) # 指数表記を抑制
print(np.array([1e10, 2e10]))
# [10000000000. 20000000000.]VBA で指数表記を解除
Sub UnsetExponential()
With Range("A1:A100")
.NumberFormat = "0" ' 整数
' .NumberFormat = "#,##0" ' 桁区切り
' .NumberFormat = "0.00" ' 小数 2 桁
' .NumberFormat = "@" ' 文字列
End With
End Sub
Sub ConvertLargeNumbersToText()
Dim cell As Range
For Each cell In Selection
If IsNumeric(cell.Value) And Len(CStr(cell.Value)) >= 13 Then
cell.NumberFormat = "@"
cell.Value = "'" & CStr(cell.Value)
End If
Next
End Sub桁落ち(15 桁問題)に注意
Excel は数値を内部的に IEEE 754 倍精度浮動小数で持つため、有効桁数は 15 桁です。16 桁目以降は 0 に置き換わります:
| 入力 | Excel 内部 | 表示 |
|---|---|---|
| 1234567890123456 | 1234567890123450 | 1.23457E+15 → 数値書式で 1234567890123450 |
| '1234567890123456 | 文字列 "1234567890123456" | 1234567890123456(正しい) |
クレカ番号・JAN コード・電話番号などは必ず文字列で扱うこと。
FAQ
Q: CSV を毎回ダブルクリックで開いて指数化される
A: Excel で先に空ブックを開き、「データ → テキスト/CSV から」で型を指定して取り込んでください。または列名を id_str 等にして「データ型を文字列」を明示。
Q: pandas で to_csv するとまた指数表記になる
A: df.to_csv("out.csv", float_format="%.0f") で桁指定。または該当列を astype(str)。
Q: 16 桁以上の正しい値を保ったまま Excel で扱いたい
A: 文字列で持つしかありません。VLOOKUP 等で比較するときも両方文字列で揃えてください。
📸 参考画像
※ 旧バージョンから引き継いだ参考画像です。手順・図解の補助としてご覧ください。
ページの作成
親となるページを選択してください。
親ページに紐づくページを子ページといいます。
例: 親=スポーツ, 子1=サッカー, 子2=野球
子ページを親ページとして更に子ページを作成することも可能です。
例: 親=サッカー, 子=サッカーのルール
親ページはいつでも変更することが可能なのでとりあえず作ってみましょう!
子ページはありません
同階層のページはありません
人気ページ
- 1 Eclipseで「サーバーに追加または除去できるリソースがありません。」の原因と対処法
- 2 tomcat の起動 / 停止ログと catalina.log・catalina.out の違い
- 3 JavaScript base URL 取得方法|window.location.origin と SSR/Node.js 対応
- 4 YouTube Data API v3 エラー一覧|403/400/404 の主要原因と切り分け
- 5 Spring Frameworkのアノテーション一覧
- 6 Laravel エラー一覧|500/Blade/DB 接続/ルーティングの代表エラー
- 7 3Dグラフィックスとは|モデリング/レンダリング/主要ソフトウェア (Blender / Maya)
- 8 【Spring】@Valueアノテーションとは
- 9 CATALINA_HOME の確認方法 (Linux / Mac)
- 10 【Spring】@Autowiredアノテーションとは
最近更新/作成されたページ
- IPv6とは|128bitアドレス・コロン16進表記/::省略・リンクローカル・SLAAC・デュアルスタック 2026-06-22 12:34:44
- VPNとは|暗号トンネル・サイト間/リモートアクセス・IPsec/SSL-VPN/WireGuardを解説 2026-06-22 12:19:10
- MAC アドレスフィルタリングの仕組みと限界 | ネットワーク入門 2026-06-22 12:19:10
- WebRTC とは ブラウザ間 P2P の音声・映像・データ通信 | ネットワーク入門 2026-06-22 12:17:25
- Web通信プロトコル入門 HTTP/2・HTTP/3・WebSocket・gRPC・WebRTC | ネットワーク入門 2026-06-22 12:17:25
- HTTP/3 (QUIC) とは UDP ベースの低遅延 Web 通信 | ネットワーク入門 2026-06-22 12:17:25
- HTTP/2 とは 多重化・HPACK・バイナリフレーム | ネットワーク入門 2026-06-22 12:17:25
- WebSocket とは 全二重リアルタイム通信 ws/wss | ネットワーク入門 2026-06-22 12:17:25
- gRPC とは HTTP/2 + Protocol Buffers の高速 RPC | ネットワーク入門 2026-06-22 12:17:25
- 証明書と認証局(CA)とは|X.509・信頼チェーン・DV/OV/EV・失効(CRL/OCSP)を解説 2026-06-22 12:17:24
- CDN とは エッジキャッシュ・TTL・Cloudflare/CloudFront | ネットワーク入門 2026-06-22 12:17:24
- iptables/nftablesとは|テーブル・チェーン・ルール例・永続化をLinux視点で解説 2026-06-22 12:17:24
- ファイアウォールとは|パケットフィルタ・ステートフル・DMZ・次世代FW(L4/L7)を解説 2026-06-22 12:17:24
- HAProxy とは frontend/backend と設定例 | ネットワーク入門 2026-06-22 12:17:24
- TLS/SSLの仕組み|ハンドシェイク・暗号スイート・前方秘匿性・証明書検証をわかりやすく解説 2026-06-22 12:17:24
コメントを削除してもよろしいでしょうか?