ページの作成
親となるページを選択してください。

親ページに紐づくページを子ページといいます。
例: 親=スポーツ, 子1=サッカー, 子2=野球
子ページを親ページとして更に子ページを作成することも可能です。
例: 親=サッカー, 子=サッカーのルール
親ページはいつでも変更することが可能なのでとりあえず作ってみましょう!
pandas(パンダス)は、表形式データを効率的に扱うPythonのデータ分析ライブラリです。行と列からなる表(テーブル)を直感的に操作でき、CSVやExcelの読み込み、データの抽出・集計・加工といった作業を少ないコードで実現できます。データ分析や機械学習の前処理を支える基盤的なツールとして広く利用されています。
| この記事の要点 |
|---|
|
pandasとは
pandasは、Pythonで表形式(テーブル形式)のデータを扱うためのオープンソースのライブラリです。スプレッドシートやデータベースのテーブルのように、行と列で構成されたデータを読み込み・加工・集計するための機能を豊富に備えています。
CSVやExcel、JSONなど多様な形式のファイルを読み込み、欠損値の処理、行や列の抽出、グループごとの集計、複数データの結合といった操作を、比較的短いコードで記述できる点が特徴です。データ分析や機械学習の前段階で行うデータの整形・前処理に頻繁に用いられます。
名前は計量経済学の用語「panel data(パネルデータ)」に由来するとされ、時系列データや多次元データの分析を念頭に設計されています。
| 主な機能 | 概要 |
|---|---|
| ファイル入出力 | CSV・Excel・JSONなどの読み込みと書き出し |
| データ抽出 | 条件指定による行・列の選択やフィルタリング |
| 集計・グループ化 | 合計・平均などの集計、グループ単位の計算 |
| 欠損値処理 | 欠損値(NaN)の検出・除去・補完 |
| 結合・連結 | 複数の表をキーや位置で結合する処理 |
2つの主要なデータ構造
pandasの中心には、SeriesとDataFrameという2種類のデータ構造があります。多くの操作はこのどちらか(または両方)を対象に行われます。
Series(1次元)
Seriesは、1列分のデータに相当する1次元のデータ構造です。値の並びに加えて、各値に対応する「インデックス(見出し)」を持ちます。リストや配列に名前付きの見出しが付いたものと考えると分かりやすいでしょう。
import pandas as pd s = pd.Series([10, 20, 30], index=["a", "b", "c"]) print(s["b"]) # 20 |
DataFrame(2次元)
DataFrameは、行と列からなる2次元の表を表すデータ構造です。表計算ソフトのシートやデータベースのテーブルに近いイメージで、pandasで最もよく使われます。各列はそれぞれ1つのSeriesに相当し、列ごとに異なるデータ型(数値・文字列・日付など)を持てます。
import pandas as pd df = pd.DataFrame({ "name": ["Alice", "Bob", "Carol"], "score": [80, 95, 70], }) print(df) |
| データ構造 | 次元 | イメージ |
|---|---|---|
| Series | 1次元 | 見出し付きの1列のデータ |
| DataFrame | 2次元 | 行と列からなる表 |
インストールとインポート
pandasはパッケージ管理ツールのpipでインストールできます。Anaconda環境では多くの場合あらかじめ含まれています。
pip install pandas |
コード内で読み込む際は、慣例として pd という別名を付けてインポートします。多くのドキュメントやサンプルがこの書き方を採用しているため、合わせておくと読みやすくなります。
import pandas as pd |
基本操作の例
CSVファイルの読み込み(read_csv)
CSVファイルは read_csv 関数でDataFrameとして読み込めます。以下は読み込むCSVデータの例です。
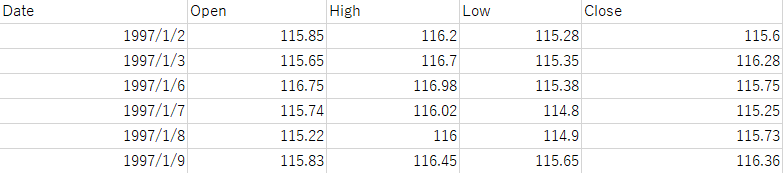
次のコードでファイルを読み込み、新しい列の追加や行の抽出、先頭の確認を行います。
import pandas as pd data_dir = "C:/test_dir/" data['Diff'] = data.Close - data.Open |
上記コードのポイントは次のとおりです。
| 記述 | 意味 |
|---|---|
| pd.read_csv(...) | CSVファイルを読み込みDataFrameを作成する |
| data['Diff'] = ... | 終値と始値の差を計算して新しい列を追加する |
| data.iloc[2:4, :] | 位置(行番号2〜3)で行を抽出する |
| data.head() | 先頭の数行を表示して内容を確認する |
実行結果の例(抽出された2行)は以下のようになります。
| Date | Open | High | Low | Close | Diff | |
|---|---|---|---|---|---|---|
| 2 | 1997-01-06 | 116.75 | 116.98 | 115.38 | 115.75 | -1.00 |
| 3 | 1997-01-07 | 115.74 | 116.02 | 114.80 | 115.25 | -0.49 |
先頭の確認(head)と列の抽出
データを読み込んだら、まず head で先頭の数行を確認すると全体像をつかみやすくなります。特定の列だけを取り出す、条件で行を絞り込む、といった操作もよく使います。
# 先頭5行を表示 df.head() # 特定の列を取り出す df["score"] # 条件で行を絞り込む(scoreが80以上) df[df["score"] >= 80] |
集計(groupby)
groupby を使うと、ある列の値ごとにデータをグループ化し、グループ単位で合計や平均などを計算できます。集計はpandasの代表的な活用例です。
import pandas as pd df = pd.DataFrame({ "team": ["A", "A", "B", "B"], "score": [80, 90, 70, 60], }) # チームごとの平均スコアを計算 result = df.groupby("team")["score"].mean() print(result) |
この例では、チームAとチームBそれぞれのスコアの平均が計算されます。
NumPyとの関係
pandasは、数値計算ライブラリNumPyを土台として構築されています。NumPyは多次元配列(ndarray)と高速な数値演算を提供するライブラリで、pandasの内部でも数値データの保持や演算に活用されています。
両者の役割はおおむね次のように整理できます。NumPyが数値の配列計算に特化しているのに対し、pandasは見出し(ラベル)付きの表形式データを扱いやすくする層を提供します。実際のデータ分析では、ラベルや欠損値を扱いやすいpandasでデータを整形し、必要に応じてNumPyの配列として数値計算を行う、といった使い分けがよく見られます。
| ライブラリ | 得意分野 |
|---|---|
| NumPy | 多次元配列の高速な数値計算 |
| pandas | ラベル付き表形式データの整形・集計 |
主な用途
pandasは、データ分析の幅広い場面で土台として使われます。代表的な用途は次のとおりです。
- データの前処理:欠損値の補完、不要な行・列の削除、型変換、表記の統一など、分析前にデータを整える作業。
- 集計・分析:グループごとの集計、相関やクロス集計、時系列データの集計などによる傾向の把握。
- 可視化の土台:整形したDataFrameを、グラフ描画ライブラリ(matplotlibなど)に渡して可視化する際の入力データとして利用。
- 機械学習の準備:学習に使う特徴量(説明変数)を表形式で整え、モデルに渡せる形に変換する。
このように、pandasは「データを読み込んで整え、分析・可視化につなげる」という流れの中心的な役割を担います。
注意したい落とし穴
pandasは便利な一方で、初心者がつまずきやすい挙動もあります。代表的なものを押さえておくと、想定外の結果やエラーを避けやすくなります。
| 落とし穴 | 内容と対策 |
|---|---|
| 欠損値(NaN) | 欠けた値はNaNとして扱われ、集計や演算の結果に影響することがある。isnull で検出し、dropna で除去、fillna で補完するなど、目的に応じて処理する。 |
| コピーとビュー | 抽出した一部に値を代入しようとすると、元データへの反映が意図したとおりにならず SettingWithCopyWarning が出ることがある。値を変更する際は .loc で行と列をまとめて指定する、明示的に .copy() を使うといった方法で意図を明確にする。 |
| 大規模データのメモリ | pandasは原則データをメモリ上に展開するため、巨大なデータでは多くのメモリを消費する。必要な列だけ読み込む、適切なデータ型を指定する、分割して読み込むなどで負荷を抑える工夫が必要になる。 |
よくある質問(FAQ)
Q1. pandasとExcelはどう違いますか?
どちらも表形式データを扱える点は共通していますが、pandasはプログラムから処理を自動化・再現できる点が大きな違いです。同じ手順を繰り返し実行したり、大量のファイルをまとめて処理したり、他のライブラリと連携したりする用途に向いています。一方、少量のデータを手軽に確認・編集するだけならExcelのほうが手軽な場面もあり、用途に応じて使い分けられます。
Q2. SeriesとDataFrameはどちらを使えばよいですか?
1列分のデータだけを扱うならSeries、行と列のある表を扱うならDataFrameが基本です。実際の分析ではDataFrameを中心に使い、その1列を取り出すと自動的にSeriesになる、という関係を意識しておくと理解しやすくなります。
Q3. import pandas as pd の「pd」は変えてもよいですか?
文法上は任意の名前を付けられますが、pd は広く使われている慣例です。多くのサンプルコードや書籍がこの別名を前提にしているため、特別な理由がなければ pd に合わせておくと、コードを読む人にとって分かりやすくなります。
ページの作成
親となるページを選択してください。
親ページに紐づくページを子ページといいます。
例: 親=スポーツ, 子1=サッカー, 子2=野球
子ページを親ページとして更に子ページを作成することも可能です。
例: 親=サッカー, 子=サッカーのルール
親ページはいつでも変更することが可能なのでとりあえず作ってみましょう!
子ページはありません
- pandas
- matplotlib
人気ページ
- 1 Eclipseで「サーバーに追加または除去できるリソースがありません。」の原因と対処法
- 2 tomcat の起動 / 停止ログと catalina.log・catalina.out の違い
- 3 JavaScript base URL 取得方法|window.location.origin と SSR/Node.js 対応
- 4 YouTube Data API v3 エラー一覧|403/400/404 の主要原因と切り分け
- 5 Spring Frameworkのアノテーション一覧
- 6 Laravel エラー一覧|500/Blade/DB 接続/ルーティングの代表エラー
- 7 3Dグラフィックスとは|モデリング/レンダリング/主要ソフトウェア (Blender / Maya)
- 8 【Spring】@Valueアノテーションとは
- 9 CATALINA_HOME の確認方法 (Linux / Mac)
- 10 【Spring】@Autowiredアノテーションとは
最近更新/作成されたページ
- IPv6とは|128bitアドレス・コロン16進表記/::省略・リンクローカル・SLAAC・デュアルスタック 2026-06-22 12:34:44
- MAC アドレスフィルタリングの仕組みと限界 | ネットワーク入門 2026-06-22 12:19:10
- VPNとは|暗号トンネル・サイト間/リモートアクセス・IPsec/SSL-VPN/WireGuardを解説 2026-06-22 12:19:10
- HTTP/2 とは 多重化・HPACK・バイナリフレーム | ネットワーク入門 2026-06-22 12:17:25
- gRPC とは HTTP/2 + Protocol Buffers の高速 RPC | ネットワーク入門 2026-06-22 12:17:25
- WebSocket とは 全二重リアルタイム通信 ws/wss | ネットワーク入門 2026-06-22 12:17:25
- WebRTC とは ブラウザ間 P2P の音声・映像・データ通信 | ネットワーク入門 2026-06-22 12:17:25
- HTTP/3 (QUIC) とは UDP ベースの低遅延 Web 通信 | ネットワーク入門 2026-06-22 12:17:25
- Web通信プロトコル入門 HTTP/2・HTTP/3・WebSocket・gRPC・WebRTC | ネットワーク入門 2026-06-22 12:17:25
- HAProxy とは frontend/backend と設定例 | ネットワーク入門 2026-06-22 12:17:24
- iptables/nftablesとは|テーブル・チェーン・ルール例・永続化をLinux視点で解説 2026-06-22 12:17:24
- CDN とは エッジキャッシュ・TTL・Cloudflare/CloudFront | ネットワーク入門 2026-06-22 12:17:24
- TLS/SSLの仕組み|ハンドシェイク・暗号スイート・前方秘匿性・証明書検証をわかりやすく解説 2026-06-22 12:17:24
- ファイアウォールとは|パケットフィルタ・ステートフル・DMZ・次世代FW(L4/L7)を解説 2026-06-22 12:17:24
- 証明書と認証局(CA)とは|X.509・信頼チェーン・DV/OV/EV・失効(CRL/OCSP)を解説 2026-06-22 12:17:24
コメントを削除してもよろしいでしょうか?