
タイトル: 使い方
//記載途中
TensorFlowを実際に使ってみましょう。
導入が済んでいない方はこちら。
OSはWindowsを前提として説明します。
3つの前提条件
チュートリアルを始める前に以下の条件を満たしているか確認してください。
・Pythonのプログラミングができる。(分からない方はこちらを参照)
・配列についてある程度分かる。(分からない方はこちらを参照)
・出来れば、機械学習についてある程度知っている。
※全く知らない方でも分かるように説明しますが、知っていればベターです
Tensors
TensorFlowの主要データ単位はTensorといいます。
TensorにはRankというものがあり、Rankは配列の次元を表します。
例えばRank1の場合は1次元配列、Rank2の場合は2次元配列といった感じです。
以下、例です。
|
|
Tensorのインポート
実際にプログラミングをしてみましょう。
以下の文言をメモ帳でもなんでもいいので書いてみましょう。
|
|
これでTensorFlowのライブラリにアクセスできます。
今後、断りが無くても基本的にこの文言は必ず書くようにしましょう。
計算グラフ
計算グラフとは、TensorFlowの一連の計算をノードのグラフに配置したものです。
試しに簡単な計算グラフを作ってみましょう。
それぞれのノードは0個以上のTensors(データ)を受け取り、一つのTensorsを結果として出力します。
ノードの中には定数のものがあります。
この定数ノードは入力値を受け付けず、単純に内部の値を出力するだけです。
node1とnode2の2つの定数の浮動小数点テンソルを作成してみましょう。
|
node1 = tf.constant(3.0, dtype=tf.float32) node2 = tf.constant(4.0) print(node1) print(node2) |
node1はfloat型と宣言していますが、node2は暗黙的にfloat型になっています。
先ほどのTensorのインポート文と合わせてPythonを起動したコマンドプロントに貼り付けましょう。
(※文法エラーが出たら文末に「;」を付けてみてください)
1回目の実行では以下の値が出力されるはずです。
|
Tensor("Const_0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32) |
注目すべきはnode1とnode2はそれぞれ3.0と4.0ではないことです。
これらは評価されると、それぞれ3.0と4.0を生成するノードです。
ノードを評価するには、セッション内で計算グラフを実行する必要があります。
では実際にセッションを開始してみましょう。
また、runメソッドで計算グラフを起動してノードを評価しましょう。
|
sess = tf.Session() print(sess.run([node1, node2])) |
上記のコードを実行すると以下の期待通りの値を得られます。
| [3.0, 4.0] |
試しにノードを組み合わせて新しいノードを作成してみましょう。
| from __future__ import print_function node3 = tf.add(node1, node2) print("node3:", node3) print("sess.run(node3):", sess.run(node3)) |
以下のような結果が得られます。
| node3: Tensor("Add:0", shape=(), dtype=float32) sess.run(node3): 7.0 |
runメソッドで実行するとnode1とnode2を加算した値がnode3になっているのが確認できます。
TensorFlowにはTensorBoardという計算グラフを絵で表す機能があります。
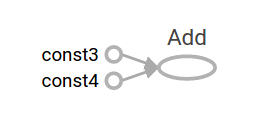
上記のグラフの入力値はプレースホルダーとすることで、値をパラメータ化することが出来ます。
| a = tf.placeholder(tf.float32) b = tf.placeholder(tf.float32) adder_node = a + b |
上記のコードはaとbという2つの入力を合算する関数です。
試しに値を渡してみましょう。
| print(sess.run(adder_node, {a: 3, b: 4.5})) print(sess.run(adder_node, {a: [1, 3], b: [2, 4]})) |
出力結果は以下の通りです。(2行目は配列同士の加算)
| 7.5 [ 3. 7.] |
TensorBoardでは以下の様に表現できます。
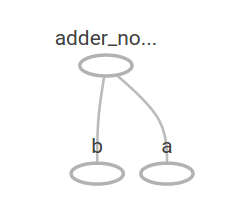
今作成したノードにもう一工夫してみましょう。
| add_and_triple = adder_node * 3. print(sess.run(add_and_triple, {a: 3, b: 4.5})) |
adder_nodeに対して計算式を付与して更に新しいノードを作成することが出来ます。
出力結果を見てみましょう。
| 22.5 |
TensorBoardではこの計算グラフは以下のように見えます。
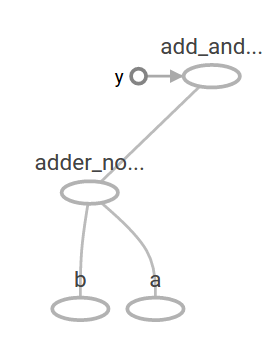
機械学習では通常、上記のような任意で値が入力可能なモデルが必要とされます。
モデルを訓練させるには変数を使う必要があります。(訓練云々の詳細は読み進めれば分かります)
変数は型と初期値で構成されます。
|
W = tf.Variable([.3], dtype=tf.float32) |
定数は「tf.constant」を呼び出すと初期化され、以後値が変わることはありませんが、変数は「tf.Variable」が呼ばれても初期化されません。
変数を初期化するには以下のプログラムを実行する必要があります。
| init = tf.global_variables_initializer() sess.run(init) |
initを実行することで全てのグローバル変数が初期化されます。
「x」はプレースホルダーなので、以下のように「x」に複数の値を渡してlinear_modelを評価してみましょう。
|
|
出力結果は以下の通りです。
| [ 0. 0.30000001 0.60000002 0.90000004] |
モデルを作って色々試してみましたが、結局モデルがどれほど有用なのかまだ今一ピンとこないと思います。
訓練データでモデルを評価するには「y」という必要な値を提供するプレースホルダーと、損失関数を書く必要があります。
損失関数とは現在のモデルが提供されたデータからどれだけかけ離れているか測ることが出来る関数です。
※言い換えると、複数の値の差を出来るだけ小さくして、答えらしきものの指標を求める関数
現在のモデルと提供されたデータの間のデルタの二乗を合計する線形回帰の標準損失モデルを使用します。
//記載途中
